研究意义
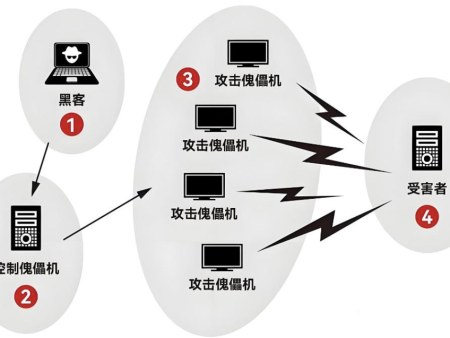
随着车联网技术的普及,车辆与车辆、车辆与基础设施之间的通信越来越频繁,这为我们的出行带来了诸多便利,但同时也让DDoS攻击等网络安全问题有了可乘之机。DDoS攻击通过大量恶意流量使网络瘫痪,影响车辆的正常通信和运行,给交通安全带来严重威胁。传统的DDoS攻击检测方法需要集中大量数据进行分析,但在车联网环境下,数据分散在不同运营公司或组织手中,难以整合。而且,这些数据涉及用户隐私,不能随意共享。这就导致传统方法在实际应用中效果受限,难以满足车联网安全的需求。
为了解决这个问题,本文提出了基于强化联邦学习的车联网DDoS攻击检测方法。强化联邦学习是一种新兴的分布式机器学习技术,它允许不同机构在不直接共享数据的情况下,协同训练一个统一的模型。通过这种方式,既保护了数据隐私,又能充分利用各方数据资源,提高模型的检测性能。
该方法利用强化学习优化联邦学习的聚合过程,使模型能够更好地适应车联网中数据分布不均衡的特点,提高检测的准确性和效率。实验结果表明,这种方法在车联网环境中表现出色,为车联网安全领域的研究提供了新的思路和方法。
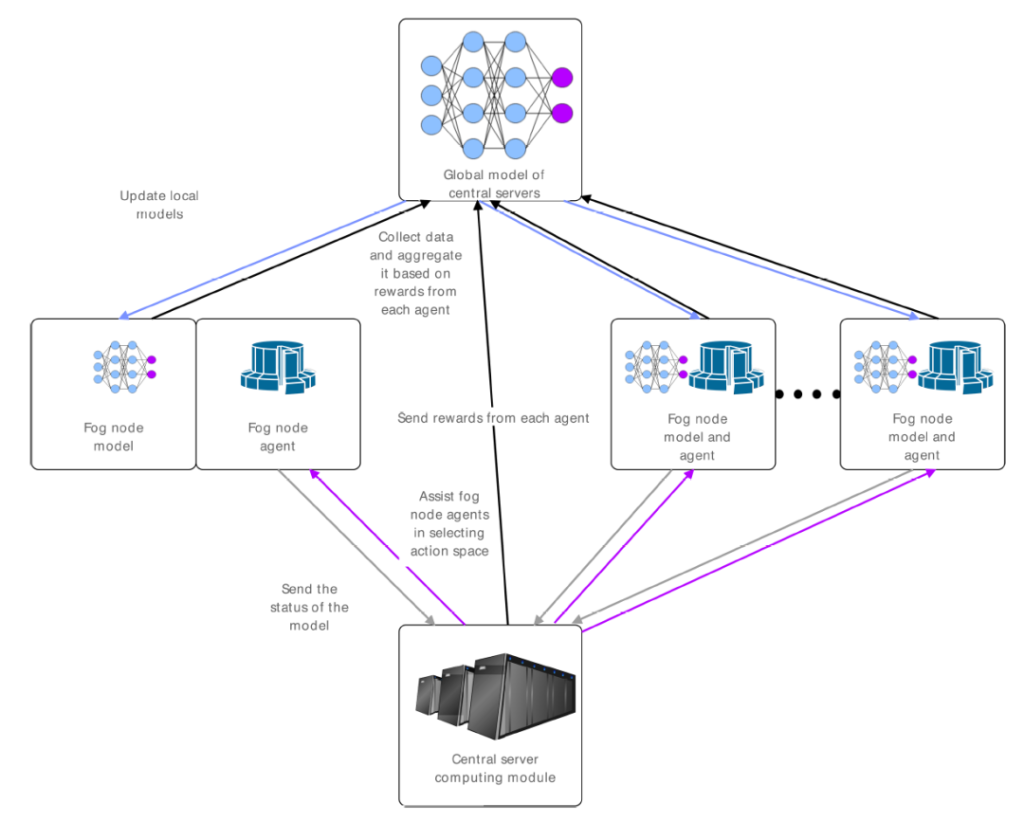
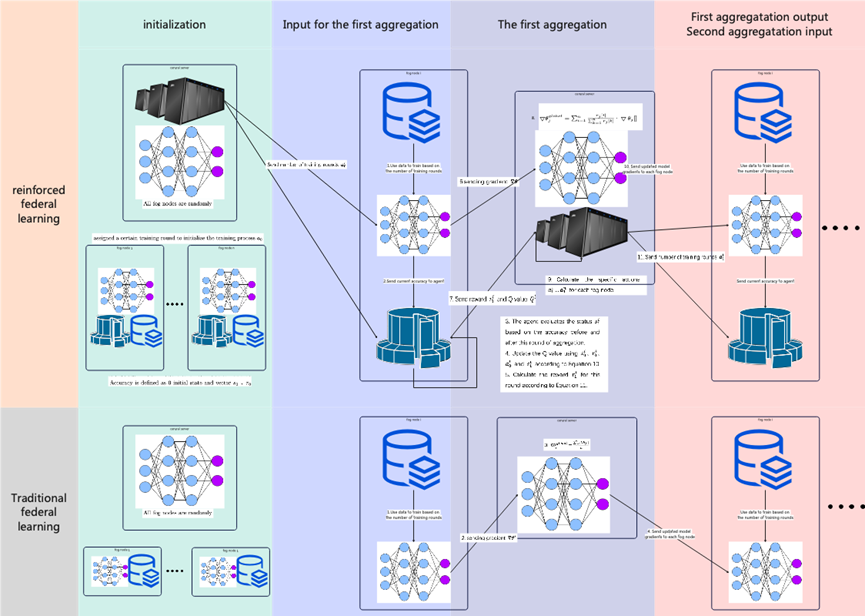
本文工作本文研究了如何利用强化联邦学习来检测车联网中的DDoS攻击。随着车联网技术的发展,车辆与车辆、车辆与基础设施之间的通信越来越频繁,这为我们的出行带来了诸多便利,但同时也让DDoS攻击等网络安全问题有了可乘之机。传统的DDoS攻击检测方法需要集中大量数据进行分析,但在车联网环境下,数据分散在不同运营公司或组织手中,难以整合。而且,这些数据涉及用户隐私,不能随意共享。这就导致传统方法在实际应用中效果受限,难以满足车联网安全的需求。提出了基于强化联邦学习的车联网DDoS攻击检测方法。强化联邦学习是一种新兴的分布式机器学习技术,它允许不同机构在不直接共享数据的情况下,协同训练一个统一的模型。通过这种方式,既保护了数据隐私,又能充分利用各方数据资源,提高模型的检测性能。本文提出的框架如图1所示,车联网中的雾节点(Fog Nodes)作为学习的参与方,利用本地数据进行训练,并将模型参数上传至边缘服务器(Edge Server)进行聚合。通过强化学习中的Q-learning算法,每个雾节点可以根据本地数据和全局反馈动态调整训练策略,优化全局模型性能。
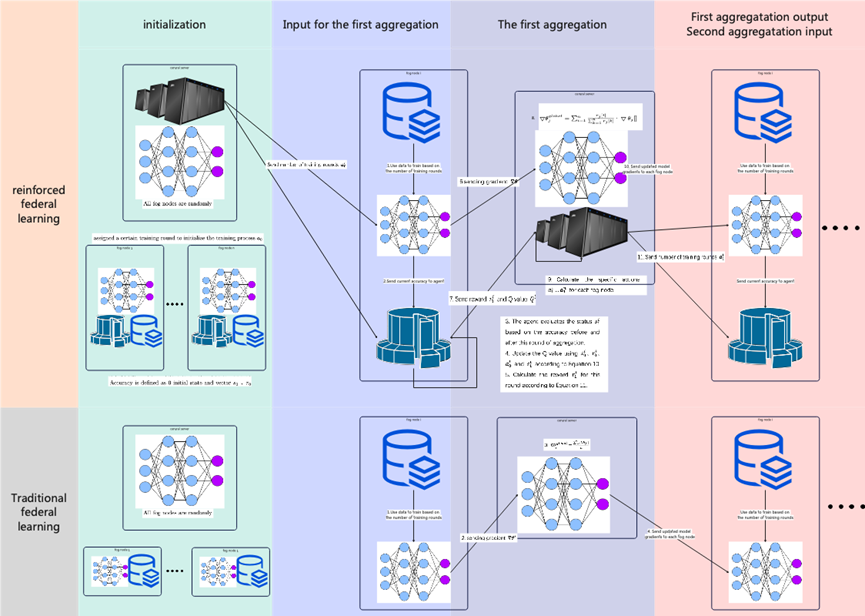
图1 强化联邦学习模型结构在强化联邦学习中,每个雾节点被视为一个智能体,通过Q-learning算法动态调整训练策略。状态(State)定义为模型准确率的变化,奖励函数(Reward)设计为鼓励模型性能提升和接近全局平均性能。通过Q值更新和策略选择,雾节点可以在每轮聚合中优化本地训练策略。与普通强化联邦学习的对比如图2所示。图2 联邦学习模型对比
本文的创新点如下:(1) 首次将强化学习引入联邦学习的聚合过程,通过Q-learning优化车联网DDoS攻击检测算法,解决了数据隐私保护与模型性能提升之间的矛盾。(2) 提出一种结合卷积神经网络(CNN)和长短期记忆网络(LSTM)的模型结构,能够有效提取车联网数据的时空特征,提升DDoS攻击检测的准确性和效率。(3) 通过与传统联邦学习算法(如FedAvg)以及多种改进算法(如MFL、FAFED、FedDA)的对比实验,证明了强化联邦学习在处理数据分布不均衡和复杂攻击场景中的显著优势。
实验结果与传统联邦学习聚合对比实验。将车联网DDoS攻击数据集打乱后,分别等分为2, 4 和8个子数据集,进行实验。实验结果如图3所示。结果表明,强化联邦学习算法相比于传统的联邦学习算法能够更早收敛,并在多轮训练后表现出更高的准确率。
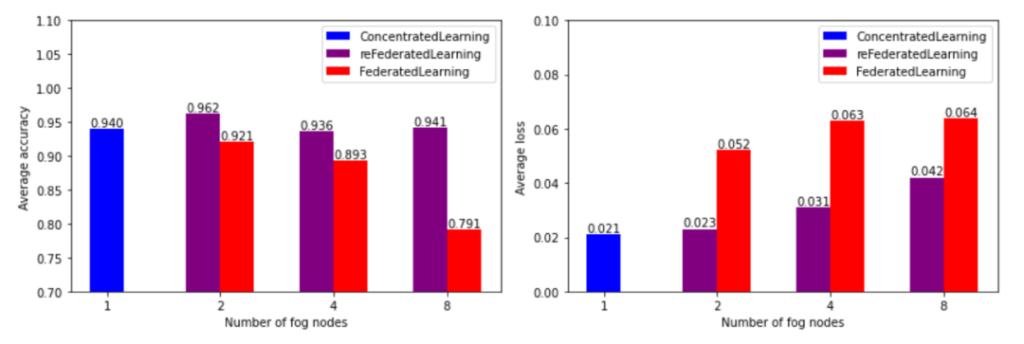
图3 不同雾节点数的实验结果
与传统联邦学习聚合对比计算开销分析。表3展示了在不同雾节点数量下,传统联邦学习与强化联邦学习完成一轮聚合所需的平均时间。表4进一步比较了在达到相同模型准确率条件下,强化联邦学习与传统联邦学习所需的训练时间。实验结果表明,强化联邦学习在达到较高准确率 (0.7和0.9) 时所需的训练时间显著少于传统联邦学习。这表明强化联邦学习能够更有效地利用雾节点的计算资源, 加速模型的收敛过程。
与改进联邦学习聚合对比实验。通过表5中与MFL, FAFED 和FedDA 的比较可以看出,强化联邦学习算法在处理non-IID数据方面具有显著优势,能够在不同雾节点数量下保持高准确率和低损失,显示出其在提升联邦学习效率方面的有效性。
综上,实验结果显示,强化联邦学习在不同雾节点数量下的收敛速度明显快于传统联邦学习算法,并且在多轮训练后表现出更高的准确率。在与多种聚合算法的对比中,强化联邦学习算法不仅在训